The Dark Secrets of BERT
07 Jan 2020 • 15 mins
15 mins
Tags:

This blog post summarizes our EMNLP 2019 paper “Revealing the Dark Secrets of BERT” (Kovaleva, Romanov, Rogers, & Rumshisky, 2019). Paper PDF: https://www.aclweb.org/anthology/D19-1445.pdf
2019 could be called the year of the Transformer in NLP: this architecture dominated the leaderboards and inspired many analysis studies. The most popular Transformer is, undoubtedly, BERT (Devlin, Chang, Lee, & Toutanova, 2019). In addition to its numerous applications, multiple studies probed this model for various kinds of linguistic knowledge, typically to conclude that such knowledge is indeed present, to at least some extent (Goldberg, 2019; Hewitt & Manning, 2019; Ettinger, 2019).
This work focuses on the complementary question: what happens in the fine-tuned BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
To answer this question, we experiment with BERT fine-tuned on the following GLUE (Wang et al., 2018) tasks and datasets:
- paraphrase detection (MRPC and QQP);
- textual similarity (STS-B);
- sentiment analysis (SST-2);
- textual entailment (RTE);
- natural language inference (QNLI, MNLI).
A brief intro to BERT
BERT stands for Bidirectional Encoder Representations from Transformers. This model is basically a multi-layer bidirectional Transformer encoder (Devlin, Chang, Lee, & Toutanova, 2019), and there are multiple excellent guides about how it works generally, including the Illustrated Transformer. What we focus on is one specific component of Transformer architecture known as self-attention. In a nutshell, it is a way to weigh the components of the input and output sequences so as to model relations between them, even long-distance dependencies.
As a brief example, let’s say we need to create a representation of the sentence “Tom is a black cat”. BERT may choose to pay more attention to “Tom” while encoding the word “cat”, and less attention to the words “is”, “a”, “black”. This could be represented as a vector of weights (for each word in the sentence). Such vectors are computed when the model encodes each word in the sequence, yielding a square matrix which we refer to as the self-attention map.
Now, a priori it is not clear that the relation between “Tom” and “cat” is always the best one. To answer questions about the color of the cat, a model would do better to focus on “black” rather than “Tom”. Luckily, it doesn’t have to choose. The power of BERT (and other Transformers) is largely attributed to the fact that there are multiple heads in multiple layers that all learn to construct independent self-attention maps. Theoretically, this could give the model the capacity to “attend to information from different representation subspaces at different positions” (Vaswani et al., 2017). In other words, the model would be able to choose between several alternative representations for the task at hand.
Most of the computation of self-attention weights happens in BERT during pre-training: the model is (pre-)trained on two tasks (masked language model and next sentence prediction), and subsequently fine-tuned for individual downstream tasks such as sentiment analysis. The basic idea for this separation of the training process into semi-supervised pre-training and supervised fine-tuning phases is that of transfer learning: the task datasets are typically too small to learn enough about language in general, but large text corpora can be used for this via the language modeling objective (and other similar ones). We could thus get task-independent, but informative representations of sentences and texts, which then could be “adapted” for the downstream tasks.
Let us note here that the exact way the “adaptation” is supposed to work is not described in detail in either BERT paper or the GPT technical report (which highlighted the pre-training/fine-tuning approach). However, if attention itself is meant to provide a way to “link” parts of the input sequence so as to increase its informativeness, and the multi-head, multi-layer architecture is needed to provide multiple alternative attention maps, presumably the fine-tuning process would teach the model to rely on the maps that are more useful for the task at hand. For instance, one could expect that relations between nouns and adjectives are more important for sentiment analysis task than relations between nouns and prepositions, and so fine-tuning would ideally teach the model to rely more on the more useful self-attention maps.
What types of self-attention patterns are learned, and how many of each type?
So what are the patterns of the self-attention in BERT? We found five, as shown below:
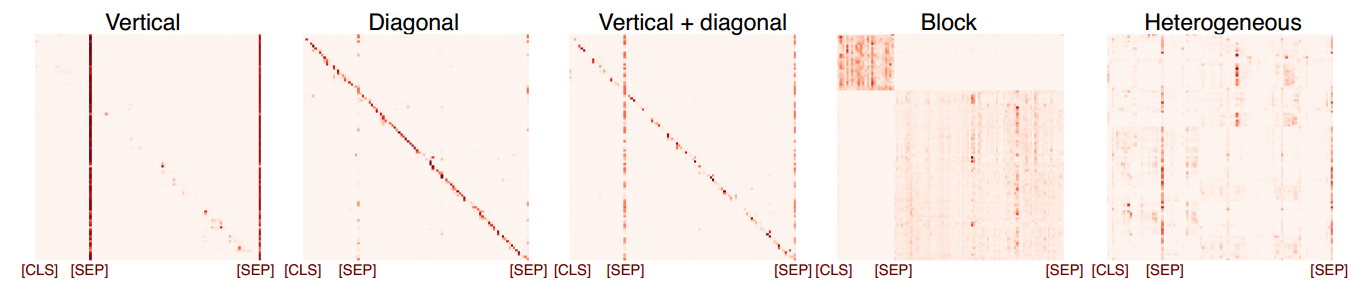
- The vertical pattern indicates attention to a single token, which usually is either the [SEP] token (special token representing the end of a sentence), or [CLS] (special BERT token that is used as full sequence representation fed to the classifiers).
- The diagonal pattern indicates the attention to previous/next words;
- The block pattern indicates more-or-less uniform attention to all tokens in a sequence;
- The heterogeneous pattern is the only pattern that theoretically could correspond to anything like meaningful relations between parts of the input sequence (although not necessarily so).
And here are the ratios of these five types of attention in BERT fine-tuned on seven GLUE tasks (with each column representing 100% of all heads in all layers):
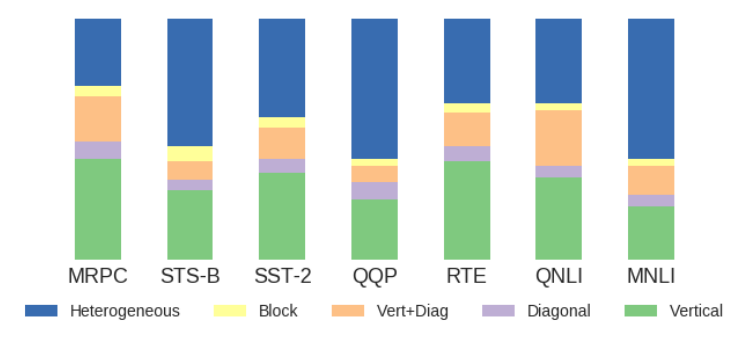
While the exact ratios vary by the task, in most cases the potentially meaningful patterns constitute less than half of all BERT self-attention weights. At least a third of BERT heads attends simply to [SEP] and [CLS] tokens - a strategy that cannot contribute much of meaningful information to the next layer’s representations. It also shows that the model is severely overparametrized, which explains the recent successful attempts of its distillation (Sanh, Debut, Chaumond, & Wolf, 2019; Jiao et al., 2019).
Note that we experimented with BERT-base, the smaller model with 12 heads in 16 layers. If it is already so overparametrized, this has implications for BERT-large and all the later models, some of which are 30 times larger (Wu et al., 2016).
Such reliance on [SEP] and [CLS] tokens could also suggest that either they somehow “absorb” the informative representations obtained in the earlier layers, and subsequent self-attention maps are simply not needed much, or that BERT overall does not rely on self-attention maps to the degree to which one would expect for this key component of this architecture.
What happens in fine-tuning?
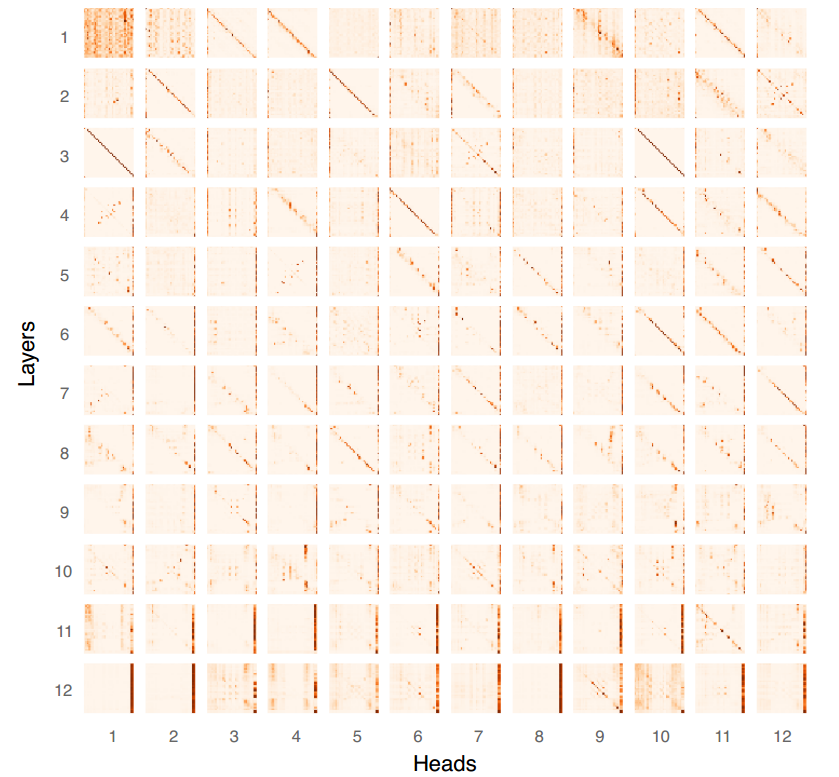
Our next question was what actually changes during the fine-tuning of BERT. The heatmap below shows the cosine similarities between flattened self-attention map matrices in each head and each layer, before and after fine-tuning. Darker colors indicate more differences in the representation. For all GLUE tasks the fine-tuning was done for 3 epochs.

We see that most attention weights do not change all that much, and for most tasks, the last two layers show the most change. These changes do not appear to favor any specific types of meaningful attention patterns. Instead, we find that the model basically learns to rely more on the vertical attention pattern. In the SST example below the thicker vertical attention patterns in the last layers are due to the joint attention to the final [SEP] and the punctuation tokens preceding it, which we observed to be another frequent target for the vertical attention pattern.
This has two possible explanations:
- the vertical pattern is somehow sufficient, i.e. the [SEP] token representations somehow absorbed the meaningful attention patterns from previous layers. We did find that the earliest layers attend to [CLS] more, and then [SEP] starts dominating for most tasks (see Fig. 6 in the paper);
- the tasks at hand do not actually require the fine-grained meaningful attention patterns that are supposed to be the main feature of the Transformers.
How much difference does fine-tuning make?
Given the vast discrepancies in the size of the datasets used in pre-training and fine-tuning, and the very different training objectives, it is interesting to investigate how much of a difference fine-tuning actually makes. To the best of our knowledge, this question has not been addressed before.
We conduct three experiments on each of the selected GLUE datasets:
- BERT performance with weights frozen from pre-training and fed to the task-specific classifiers;
- BERT performance with a model randomly initialized from normal distribution, and fine-tuned on task datasets for 3 epoches;
- BERT performance with the official pretrained BERT-base model, fine-tuned on task datasets for 3 epochs.
The results of this experiment were as follows:
| Dataset | Pretrained | Random+finetuned | Pretrained+finetuned | Metric | Dataset size |
|---|---|---|---|---|---|
| MRPC | 31.6 | 68.3 | 82.3 | Acc | 5.8K |
| STS-B | 33.1 | 2.9 | 82.7 | Acc | 8.6K |
| SST-2 | 49.1 | 80.5 | 92 | Acc | 70K |
| QQP | 60.9 | 63.2 | 78.6 | Acc | 400K |
| RTE | 52.7 | 52.7 | 64.6 | Acc | 2.7K |
| QNLI | 52.8 | 49.5 | 84.4 | Acc | 130K |
| MNLI-m | 31.7 | 61.0 | 78.6 | Acc | 440K |
While it is clear that pretraining + fine-tuning setup yields the highest results, the random + fine-tuned BERT is doing disturbingly well on all tasks except textual similarity. Indeed, for sentiment analysis it appears that one could get 80% accuracy with randomly initialized and fine-tuned BERT, without any pre-training. Given the scale of the large pre-trained Transformers, this raises serious questions about whether the expensive pre-training yields enough bang for the buck. It also raises serious questions about the NLP datasets that apparently can be solved without much task-independent linguistic knowledge that the pre-training + fine-tuning setup was supposed to deliver.
Update 18.01.2020: Thanks to Sam Bowman for pointing out that the random BERT results are overall comparable with pre-Transformer GLUE baselines, and are best interpreted as a reminder of the degree to which these tasks are solvable without deep linguistic knowledge. NLP community needs much more work on harder datasets that actually require such knowledge, and in the interim we should at least switch to SuperGLUE.
Note that GLUE baselines and most published results on these tasks use word embeddings or count-based word vectors as inputs, while our random BERT was fully random. Thus direct comparison is not entirely fair. However, for SST in particular such comparison can be made with the original Recursive Neural Tensor Network (Socher et al., 2013). This 2013 model is tiny in comparison and also takes random vectors as input representations, but it beats our random+fine-tuned BERT by 7 points on binary classification.
Are there any linguistically interpretable self-attention heads?
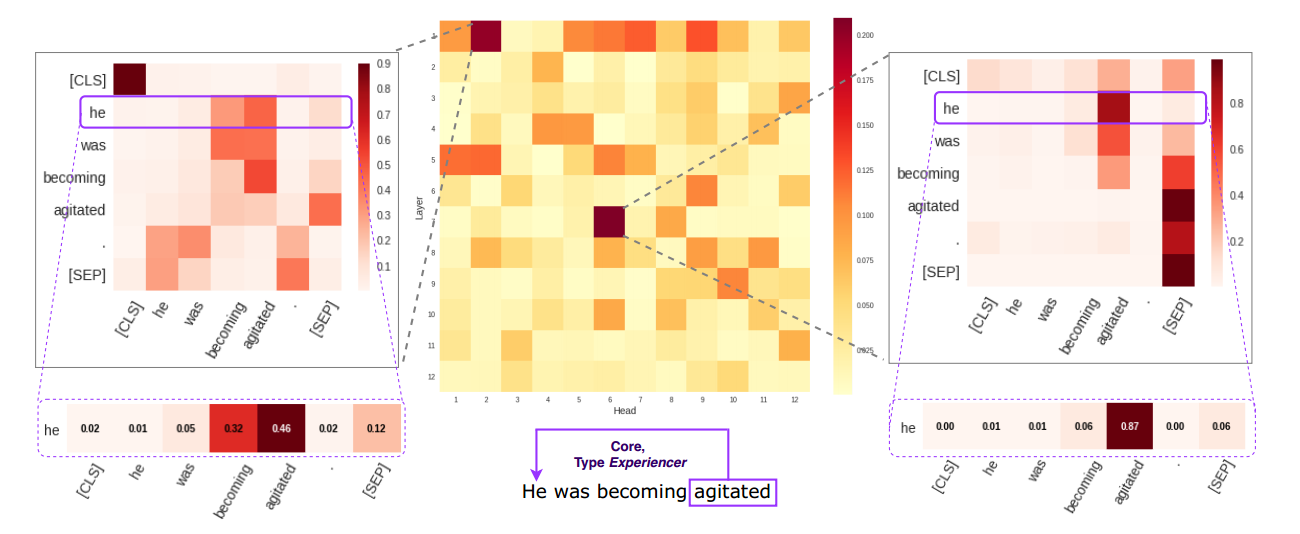
Several studies at this point tried to locate self-attention heads that encode specific types of information, but most of them focused on syntax. We conducted an experiment focusing on frame semantic elements: we extracted from FrameNet 1.7 (Baker, Fillmore, & Lowe, 1998) 473 sentences which were at most 12 tokens in length (to reduce the number of sentences evoking multiple frames), and which had a core frame element at a distance of at least 2 tokens from the target word (irrespective of its syntactic function). In the example below, it is the relation between the Experiencer and the participle “agitated” that evokes the Emotion_directed frame. Arguably, such relations are indeed core to understanding the situation described by a given sentence, and any mechanism claiming to provide linguistically informative self-attention maps should reflect them (possibly among many other relations).
We obtained representations of these sentences by pre-trained BERT, calculating the maximum weights between token pairs corresponding to the annotated frame semantic relations. Fig. 5 represents the averages of these scores for all examples in our FrameNet dataset. We found two heads (head 2 in layer 1, head 6 in layer 7) that attended to these frame semantic relations more than the other heads.
But… what information actually gets used at inference time?
We believe it would be too rash to conclude from probes of pre-trained BERT weights that certain information is actually encoded. Given the size of the model, it might be possible to find similar proof of encoding for any other relation (and the fact that Jawahar et al. found no significant difference between different decomposition schemes points in that direction (Jawahar, Sagot, & Seddah, 2019)). The real question is whether the model learns to actually rely on that information at inference time.
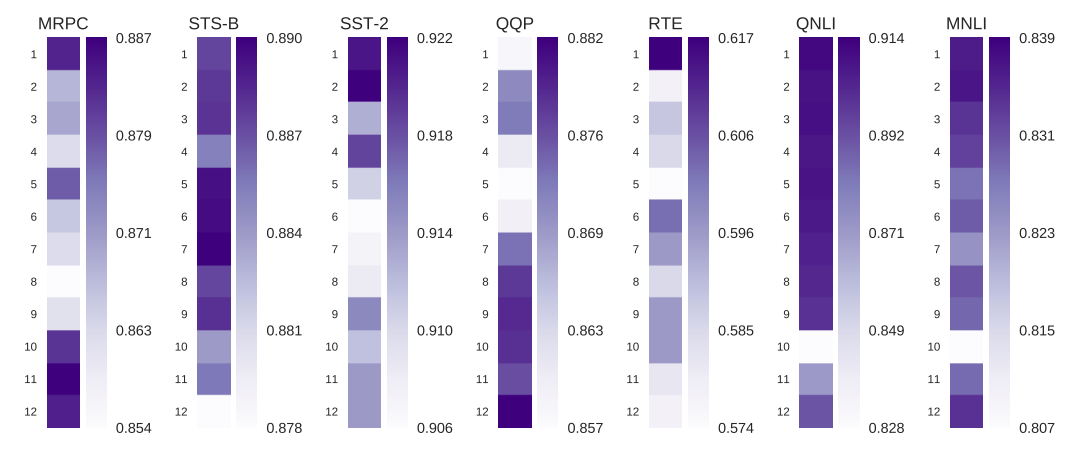
To see whether the two heads we identified as useful for encoding frame semantic relations actually get used by fine-tuned BERT, we performed an ablation study, disabling one head at a time (i.e. replacing the learned attention weights with uniform attention). Fig. 6 shows a heatmap for all GLUE tasks in our sample, with each cell indicating the overall performance when a given head was switched off. It is clear that while the overall pattern varies between tasks, on average we are better off removing a random head - including those that we identified as encoding meaningful information that should be relevant for most tasks. Many of the heads can also be switched off without any effect on performance, again pointing at the fact that even the base BERT is severely overparametrized.
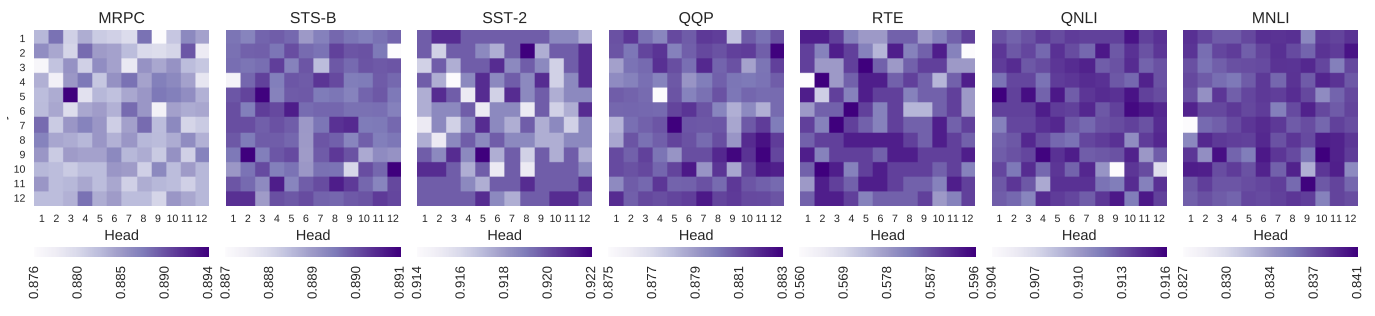
Similar conclusions were reached independently for machine translation task, with zeroing attention weights rather than replacing them with uniform attention (Michel, Levy, & Neubig, 2019). We further show that this observations extends not to just heads, but whole layers: depending on the task, a whole layer may be detrimental to the model performance!
Discussion
Our key contribution is that while most studies of BERT focused on probing the pre-trained model, we raised the question of what happens in fine-tuning, and just how meaningful the representations obtained with the self-attention mechanism are. So far, we were unable to find evidence of linguistically meaningful self-attention maps being crucial for the performance of fine-tuned BERT.
Our results contribute to the ongoing discussion about the properties of Transformer-based models in the following directions:
a) BERT is heavily overparametrized. In our experiments we disabled only one head at a time, and the fact that in most cases the model performance did not suffer suggests that many heads have functional duplicates, i.e. disabling one head would not harm the model because the same information is available elsewhere. This result points at overparametrization and explains the success of the smaller BERTs like AlBERT and TinyBERT.
Such overparametrization means that BERT may have some highly important heads with linguistically meaningful self-attention patterns after all, but to prove that, we would have to try disabling all possible head combinations (which is not feasible). A promising alternative was suggested in a contemporaneous study: (Voita, Talbot, Moiseev, Sennrich, & Titov, 2019) identified the “important” heads of the base Transformer by fine-tuning the model with a regularized objective that had a pruning effect.
b) BERT does not need to be all that smart for these tasks. The fact that BERT can do so well on most GLUE tasks without pre-training suggests that to a large degree they can be solved without much of language knowledge. Instead of verbal reasoning, it may learn to rely on various shortcuts, biases and artifacts in the datasets to arrive at the correct prediction. In that case its self-attention maps do not necessarily have to be meaningful to us. This finding supports the recent discoveries of problems with many current datasets (Gururangan et al., 2018; McCoy, Pavlick, & Linzen, 2019).
An alternative explanation is that BERT’s success is due to black magic something other than self-attention. For instance, the high amount of attention to punctuation after fine-tuning could mean that the model actually learned to rely on some other component, or there is some deep pattern we cannot comprehend. Also, the degree to which attention can be used to explain model predictions in principle is currently being debated (Jain & Wallace, 2019; Serrano & Smith, 2019; Wiegreffe & Pinter, 2019).
References
- Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. CoRR, abs/1609.08144. [PDF]
- Wiegreffe, S., & Pinter, Y. (2019). Attention Is Not Not Explanation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 11–20. https://doi.org/10.18653/v1/D19-1002 [PDF]
- Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–355. Brussels, Belgium: Association for Computational Linguistics. [PDF]
- Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5797–5808. https://doi.org/10.18653/v1/P19-1580 [PDF]
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. NIPS, 5998–6008. Long Beach, CA, USA. [PDF]
- Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., & Potts, C. (2013). Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–1642. [PDF]
- Serrano, S., & Smith, N. A. (2019). Is Attention Interpretable? Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2931–2951. https://doi.org/10.18653/v1/P19-1282 [PDF]
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS 2019. [PDF]
- Michel, P., Levy, O., & Neubig, G. (2019). Are Sixteen Heads Really Better than One? NeurIPS. [PDF]
- McCoy, T., Pavlick, E., & Linzen, T. (2019). Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3428–3448. https://doi.org/10.18653/v1/P19-1334 [PDF]
- Kovaleva, O., Romanov, A., Rogers, A., & Rumshisky, A. (2019). Revealing the Dark Secrets of BERT. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 4356–4365. https://doi.org/10.18653/v1/D19-1445 [PDF]
- Jiao, X., Yin, Y., Shang, L., Jiang, X., Chen, X., Li, L., … Liu, Q. (2019). TinyBERT: Distilling BERT for Natural Language Understanding. ArXiv Preprint ArXiv:1909.10351. [PDF]
- Jawahar, G., Sagot, B., & Seddah, D. (2019). What Does BERT Learn about the Structure of Language? ACL 2019, 3651–3657. Florence, Italy. [PDF]
- Jain, S., & Wallace, B. C. (2019). Attention Is Not Explanation. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 3543–3556. [PDF]
- Hewitt, J., & Manning, C. D. (2019). A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4129–4138. [PDF]
- Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S., & Smith, N. A. (2018). Annotation Artifacts in Natural Language Inference Data. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 107–112. https://doi.org/10.18653/v1/N18-2017 [PDF]
- Goldberg, Y. (2019). Assessing BERT’s Syntactic Abilities. ArXiv:1901.05287 [Cs]. [PDF]
- Ettinger, A. (2019). What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models. ArXiv:1907.13528 [Cs]. [PDF]
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. [PDF]
- Baker, C. F., Fillmore, C. J., & Lowe, J. B. (1998). The Berkeley Framenet Project. Proceedings of the 17th International Conference on Computational Linguistics, 1, 86–90. Association for Computational Linguistics. [PDF]