Question Answering for Artificial Intelligence (QuAIL)
27 Feb 2020 • 24 mins
24 mins
Tags:

This blog post summarizes our AAAI 2020 paper “Getting Closer to AI-complete Question Answering: A Set of Prerequisite Real Tasks” (Rogers, Kovaleva, Downey, & Rumshisky, 2020).
Links: leaderboard, submission instructions, data in json and xml formats. Challenge set description here. You can also access the data from HuggingFace’s NLP Datasets and browse the data in their online viewer.
We thank the anonymous reviewers for their insightful comments. The first author is also grateful for the opportunities to discuss this work at an invited talk at AI2 and a keynote at Meta-Eval workshop. Among many people whose comments made this post better are Noah Smith, Matt Gardner, Daniel Khashabi, Ronan Le Bras (AI2), Chris Welty, Lora Aroyo, and Praveen Paritosh (Google Research).
Update of 23.04.2020: after the publication of QuAIL we ran additional experiments on stability of BERT. Unless specified otherwise, this post reports our updated estimates of its performance and revisits some of our original analysis.
Since 2018 there has been an explosion of new datasets for high-level verbal reasoning tasks, such as reading comprehension, commonsense reasoning, and natural language inference. However, many new datasets get “solved” almost immediately, prompting concerns about data artifacts and biases. Our models get fooled by superficial cues (Jia & Liang, 2017; McCoy, Pavlick, & Linzen, 2019) and so may achieve seemingly super-human accuracy without any real verbal reasoning skills.
One of the top reasons for the datasets being so easy is poor diversity of data. Deep learning requires large training sets, which typically are generated by crowd workers provided with minimal instructions. This may result in large portions of data exhibiting spurious patterns that the model learns to associate with a particular label. For example, the word “never” is strongly predictive of the contradiction label in SNLI (Gururangan et al., 2018), simply because negating was an easy strategy for the crowd workers to generate contradictory statements. If a few such patterns cover large portions of the data, we have a problem.
To avoid this, fundamentally we need to reduce the amount of spurious correlations with predicted labels, which would hopefully force our models to learn generalizable patterns rather than dataset-specific “shortcuts”. The solution to this problem that we explored in QuAIL is balancing different types of data within one dataset. This does not guarantee the absence of any biases, but it should decrease the likelihood of a single bias affecting a large portion of data. In particular, we experiment with 4x9 design: 4 domains by 9 question types, each with approximately the same number of questions.
In addition to reducing the biases, this approach should also enable diagnostics of both the models and the data: finding what the model can and cannot do, and whether any parts of data look suspiciously easy. When we started working on QuAIL, the only other reading comprehension dataset with annotation for question types was the original bAbI (Weston et al., 2016), which consisted of toy tasks with synthetic data.
It turns out, there are very good reasons why this approach has not been explored before. We have learned a lot from this project, and here are the main takeaways:
- it is possible to crowdsource a RC dataset balanced by question types and domains;
- balanced design is great for model and data diagnostics;
- reasoning over the full spectrum of uncertainty is harder for humans than for machines;
- paraphrasing hurts even BERT.
Balanced and diverse data is great!
QuAIL is a multi-domain RC dataset featuring news, blogs, fiction and user stories. Each domain is represented by 200 texts, which gives us a 4-way data split. The texts are 300-350 word excerpts from CC-licensed texts that were hand-picked so as to make sense to human readers without larger context. Domain diversity mitigates the issue of possible overlap between training and test data of large pre-trained models, which the current SOTA systems are based on. For instance, BERT is trained on Wikipedia + BookCorpus, and was tested on Wikipedia-based SQuAD (Devlin, Chang, Lee, & Toutanova, 2019).
In addition to balancing the domains, we balance the number of questions across 9 question types:
- text-based questions (the information should be found in the text):
- reasoning about factual information in the text (e.g. What did John do?);
- temporal order of events (e.g. When did X happen - before, after, or during Y?);
- character identity (e.g. Who ate the cake?);
- world knowledge questions (rely on some kind of inference about characters and events, based on information in the text and world knowledge):
- causality (e.g. Why did John eat the cake?);
- properties and qualities of characters (e.g. What kind of food does John probably like?);
- belief states (e.g. What does John think about Mary?);
- subsequent state after the narrated events (e.g. What does John do next?);
- duration of the narrated events (e.g. How long did it probably take John to eat the cake?);
- unanswerable questions are questions for which the information is not found in the text, and all answer options are equally likely (e.g. What is John’s brother’s name?)
In terms of the format, QuAIL is a multi-choice dataset where all questions have 3 answer options, as well as “not enough information” (NEI) option, which is the correct answer for the unanswerable questions. The data looks as follows.

Overall, the above design gives us the total of 4 x 9 balanced subsets of the data, which are all labeled for question types and domains. The labels can be used for diagnosing both the models (what they can and can’t do) and the data (finding the sections that are suspiciously easy).
So, how do our models do with this data? This is the place in the paper where you usually get a table with the results of a few baselines. If the dataset is partitioned like QuAIL, you get a larger table that tells you how successful your model was on different types of questions – and that might tell you something useful about how it works. We experimented with a simple heuristic baseline (picking the longest answer), a classic PMI solver that should prefer the answers with significant lexical overlap with the text, a BiLSTM baseline using word embeddings, BERT (Devlin, Chang, Lee, & Toutanova, 2019), and TriAN - a ConceptNet-based system that won SemEval2018-Task11 (Wang, Sun, Zhao, Shen, & Liu, 2018). The columns show model accuracy (percentage of all questions of the corresponding types, with the best result per question type in bold). The random guess accuracy is 25%.
Table 1. Baseline system accuracy
| Question type | LongChoice | LSTM | PMI | TriAN | BERT |
|---|---|---|---|---|---|
| Temporal order | 36.3 | 37 | 42.5 | 55.5 | 54.58 |
| Character identity | 32.3 | 32.4 | 48.3 | 53.1 | 47.08 |
| Causality | 46.8 | 38.5 | 57.8 | 60.1 | 61.67 |
| Factual | 35.9 | 20.2 | 57.5 | 55.0 | 59.58 |
| Subsequent state | 29.5 | 36.8 | 32.9 | 47.5 | 51.53 |
| Event duration | 33.6 | 43.6 | 37 | 56.9 | 62.92 |
| Entity properties | 35 | 30.8 | 33.7 | 45.8 | 55.0 |
| Belief states | 30.9 | 34.7 | 37.5 | 43.3 | 59.58 |
| Unanswerable questions | 12.2 | 51.8 | 23.3 | 65.0 | 30.83 |
| All questions | 35.6 | 37.2 | 41.8 | 54.7 | 53.94 |
* BERT results were updated after the paper publication, see below
BERT leads in all categories, including the world knowledge questions where it could be expected to be inferior to TriAN: a ConceptNet-based system made specifically for this kind of multi-choice QA. This suggests either that it contains more of world knowledge than ConceptNet, or its world knowledge is more relevant to QuAIL. However, on average world knowledge questions are more difficult than text-based questions. Note that on factual questions it is only 3 points ahead of PMI.
A key advantage of categories in QuAIL design is that heuristic baselines are helpful for finding suspiciously easy sections of data. Our LongChoice heuristic is very successful on causality questions, which suggests that the Turkers mostly wrote the long causal explanations for the correct answers but not distractors. Since causality is also the second easiest category for BERT, it is possible that this bias helps it as well. The partitioning methodology enables the dataset authors to locate the problematic parts and fix them, e.g. to release a more difficult version of the dataset.
Partitioning across domains is helpful as well. Consider the following breakdown of BERT results:
Table 2. BERT accuracy in different domains
| Question category | Fiction | News | Blogs | User stories |
|---|---|---|---|---|
| Text-based | 45.5 | 38.8 | 60.5 | 61.6 |
| World knowledge | 61 | 58 | 58.3 | 55.6 |
| Unanswerable | 58.3 | 68.3 | 40 | 50 |
| All questions | 55.5 | 52.7 | 57 | 57 |
* Results for the original experiment reported in the published paper
Small difference between categories are likely due simply to model instability, but unanswerable questions are suspiciously easy in the news (68% accuracy), but not in blogs (40%). This could be due to the fact that news style and vocabulary are quite far from everyday speech, making the crowdworkers’ distractor options easier to detect.
Crowdsourcing specific question types is hard (but not impossible)
So if partitioning datasets in sections by question types and domains is so great, why is nobody doing it?
Well, it’s very difficult.
First, not all texts are suitable for all question types: for example, you wouldn’t be able to do much for coreference or causality given a description of a landscape. One of the most frequent questions we got from reviewers and the audience was how we chose the question types and texts. The answer is, we chose them together by much trial and error, to maximize the number of possible questions for the same text. The domain options were also limited to non-specialized texts that could be processed by crowd workers.
Second, the crowd workers really do not want to write diverse questions. Most other studies that did not control for question types while they were generated provide a breakdown by the first word of the question (which is very crude, as causality, factual, world knowledge questions could all start with what), or an analysis of a small sample that they manually annotated. The reported distributions tend to be unbalanced, usually with factoid questions making the bulk of the data and a long tail of other question types. For example, in NarrativeQA (Kocisky et al., 2018) 25% of questions are about descriptions, 10% - about locations (both corresponding to our “factual” category, since the answers are supposed to be found in the narrative), 31% of questions are on character identity, about 10% causality, and less than 2% for event duration.
This is what we found as well: the easiest questions to generate are simple factoid questions (“John ate a cake” -> “What did John eat?”). Our form showed the text and sections corresponding to different question types, with different examples and instructions for each type. Even with the examples, the most frequent kind of error would be factoid questions instead of any other question type. Also, unanswerable questions could be of any type, but what we got was mostly factoid.
So, how do you ensure question diversity? In this work we experimented with two strategies:
1) Crowd-assisted writing: the crowdsourced questions were checked by additional student annotators, who were asked to correct any language errors, any ambiguous or incorrect answers, and also rewrite the questions of the wrong type.
2) Crowdsourcing with automatic keyword-based validation: the crowd workers had the same interface to work with, but now they got automatic feedback if their questions did not match our lists of relevant keywords (e.g. “because”, “reason” for causality questions).
Based on our experience, we recommend the latter workflow, as it is much faster and comparable in terms of data quality. In a manually annotated sample, 11.1% questions in workflow (1) had answer problems vs 16.7% for workflow (2), and 6.7% questions were of the wrong type, vs 11.7% for workflow (2).
Workflow (1) has the advantage of reducing language errors: many Turkers were clearly not native speakers, although we followed the common practice of limiting the pool of workers to those from the US and Canada with at least 1000 accepted HITs and 97% approval. However, we found that (1) also introduced extra question type biases. In our sample, 25% questions that were of the entity properties type, according to the annotator, were in fact on causality. None of the Turkers made this type of error. This is likely due to the recently pointed out annotator bias problem (Geva, Goldberg, & Berant, 2019): people processing large amounts of data are likely to develop their own heuristics for dealing with it. If a few annotators are processing a lot of crowdsourced data, the same effect can be expected. While completely relying on multiple Turkers increases the likelihood of noise, it also increases diversity.
The good news is that automatic keyword-based validation produces the Hawthorne effect on the crowd workers. Similarly to people making more donations to charities when they perceived they were being watched, our checks decreased the number of people who simply copy-pasted example questions or contributed nonsensical data.
World knowledge + text-based + unanswerable questions = trouble
To recap, QuAIL is the first verbal reasoning benchmark that attempted to combine text-based questions, world knowledge questions, and unanswerable questions. For the former, the answer is directly in the text. In world knowledge questions the system needs to combine the facts of the specific context with external knowledge, which makes one of the proposed answer options more likely than the others. In unanswerable questions, we asked the crowd workers to specify answer options that were are equally likely. All QuAIL questions have 3 human-generated answer options and “not enough information” option, which is the correct one for unanswerable questions.
Our rationale for trying this text-based + world knowledge + unanswerable question setup was that humans in everyday life are demonstrably able to perform reasoning across the full spectrum of uncertainty. A brief example:
Suppose you want to buy a new laptop, and are considering several options. You will probably want to know how much RAM you can get, and you know where to find the answer to that question (in the model description). That’s a perfect-information, text-based question. Now, say you also want to know whether the video calls will feature your nostrils. You know that you can’t just google for this information, but you can look at the photo and use your external knowledge (of optics, in this case) to deduce the answer. Finally, you probably also want to know how the keyboard feels - but this question is unanswerable, the only way is tell is to try typing on that keyboard yourself.
So, in real life humans are able to reason under all three uncertainty settings. But they don’t want to! When we presented our student volunteers with a sample of QuAIL data (180 questions, 10 texts, 2 questions of each type per text), the agreement with the Turkers was only .6 (Kripperndorff’s alpha). However, when we split the same questions into text-based+unanswerable questions (≈ SQuAD 2.0 setup) and world knowledge questions (≈ SWAG setup), the agreement was considerably higher - even though the questions were exactly the same!
This is an interesting result in “machine learning psychology” (© Chris Welty, discussion at Meta-Eval workshop) which deserves further investigation. One of the reasons for the stark difference between all-questions, SQuAD and SWAG setups could be that humans are uncomfortable admitting that they don’t know something, and so in the unanswerable questions they may opt to make a guess rather than select the “not enough information option”. Another possibility is that borderline cases of uncertainty estimation are mentally taxing, and humans are not good at performing this at scale because of ego depletion (Schmeichel, Vohs, & Baumeister, 2003). For example, if we go to the supermarket to get some jam, are faced with too many equally good options, and ruminate over which one to buy, this will leave us less able to make better decisions later that day.
Note however that the systems we evaluated do NOT have this problem when evaluated in all-questions setup:
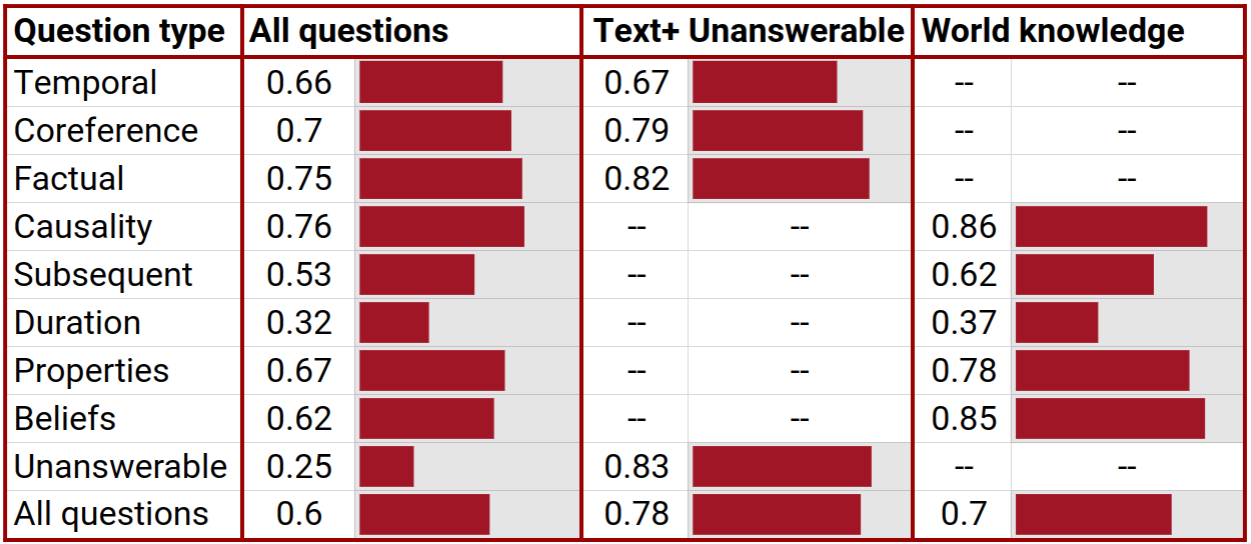
Table 3. Humans vs NLP systems
| Question type | Human: all questions |
Human: text+ unanswerable |
Human: world knowledge |
TriAN | BERT |
|---|---|---|---|---|---|
| Temp. order | 0.66 | 0.67 | – | 55.5 | 59.49 |
| Char. identity | 0.7 | 0.79 | – | 53.1 | 59.38 |
| Factual | 0.75 | 0.82 | – | 55 | 60.23 |
| Causality | 0.76 | – | 0.86 | 60.1 | 63.72 |
| Subsequent | 0.53 | – | 0.62 | 47.5 | 51.53 |
| Duration | 0.32 | – | 0.37 | 56.9 | 60.58 |
| Properties | 0.67 | – | 0.78 | 45.8 | 48.94 |
| Beliefs | 0.62 | – | 0.85 | 43.3 | 55.65 |
| Unanswerable | 0.25 | 0.83 | – | 65 | 69.12 |
| Total | 0.6 | 0.78 | 0.7 | 54.7 | 58.74 |
* BERT results are updated after the paper publication, see below
For many categories BERT is close to humans in the all-questions setup (in which the humans perform worse); but it does not struggle with unanswerable questions like they do. Manual analysis suggests that most unanswerable questions resemble factual questions (e.g. “What did John eat?”), so if the model simply learned to distinguish the unanswerable questions by their form of the question, it would get a low score on factual questions. Some of its success must be due to the above-mentioned problem with unanswerable questions in the news, and it is possible there are other problems that we missed. Still, this is a case where in principle an NLP system could show “superhuman” performance on a verbal reasoning task – simply by virtue of machines not getting mentally tired the way we do.
Finally, note that the duration questions are consistently difficult for humans in both all-questions and world-knowledge setups, but not particularly difficult for BERT. It is possible that the high model performance is due to the fact that people tend to use only a few typical duration units (e.g. “five minutes” rather than “six” or “four”), and that collocation information provides good hints (e.g. “life” is more associated with “years” than “hours”). Low human performance indicates either a higher rate of genuine disagreements about expected event durations, or lower tolerance for guesswork on this topic. In McTaco (Zhou, Khashabi, Ning, & Roth, 2019) this question type required a lot of filtering out data that humans disagreed on (source: personal communication).
Paraphrasing hurts
Since many of the questions formulated by crowd workers could be solved with simple cooccurrence counts, we conducted an additional experiment to see how much the performance would be hurt if these surface cues were taken away. The authors created paraphrased versions of questions for 30 fiction texts (556 questions in total), aiming in particular to reduce lexical cooccurrences between the text and the words in the question and the correct answer1. Then we trained our baseline models on all non-paraphrased data and tested on this extra challenge set.
Table 4. Accuracy on paraphrased questions
| Qtype | TriAN | BERT |
|---|---|---|
| Temporal | 0.51 (0.06) | 0.24 (-0.25) |
| Coreference | 0.42 (-0.11) | 0.31 (-0.13) |
| Factual | 0.32 (-0.21) | 0.4 (-0.12) |
| Causality | 0.33 (-0.2) | 0.3 (-0.27) |
| Subsequent | 0.23 (-0.12) | 0.3 (-0.18) |
| Duration | 0.62 (0.0) | 0.48 (-0.13) |
| Properties | 0.31 (-0.06) | 0.42 (0.02) |
| Belief states | 0.26 (-0.27) | 0.31 (-0.39) |
| Unanswerable | 0.55 (-0.1) | 0.48 (-0.13) |
| All questions | 0.4 (-0.11) | 0.36 (-0.17) |
* BERT results for the original experiment reported in the published paper
The drop in performance is clearly significant, particularly for BERT. With respect to factual questions, this means that it does rely on lexical cooccurrence counts to a large degree. These results complement the evidence of BERT’s susceptibility to shallow heuristics in NLI (McCoy, Pavlick, & Linzen, 2019).
For other question types, we interpret our results as suggesting that many of the correct answer options were initially formulated with lexical cues from the text, even for world knowledge questions, whereas the distractors were more often made up, and that made the data easier for the models. In particular, this seems to be true for the causality questions that also had the longest-answer bias.
Discussion: other ways to increase question diversity
Increasing data diversity and avoiding spurious correlations with predicted labels are two fundamental challenges for the NLP dataset design. In developing QuAIL, we focused on one possible direction: diversifying data through balanced dataset design and partitioning by question types and domains.
In parallel with our work, the community has been exploring adversarial data development. Datasets can be collected with a model-in-the-loop that rejects “easy” entries (Dua et al., 2019), or filtered post-hoc (Bras et al., 2019). This is very promising, and we intend in particular to experiment with adversarial selection of distractors, since human-written distractors are often easy to detect through text cooccurrence counts.
However, the adversarial approach also has caveats: its success ultimately depends on the hypothesis of a specific model-in-the-loop, which may not generalize to other models. For instance, the authors of PIQA used BERT as the adversary, and in the final dataset it performed worse than GPT-2 (Bisk, Zellers, Bras, Gao, & Choi, 2020), although generally it outperforms GPT-2 on many other benchmarks. There is also recent evidence that stronger adversaries change the question distribution in a way that prevents some weaker models from generalizing to the original distribution (Bartolo, Roberts, Welbl, Riedel, & Stenetorp, 2020).
While QuAIL aimed to collect balanced question types for the same texts, the community also started experimenting with multi-dataset learning (Dua, Gottumukkala, Talmor, Gardner, & Singh, 2019). A model trained on one RC dataset does not necessarily generalize to another (Yatskar, 2019), but training on multiple datasets will create more general-purpose systems (Talmor & Berant, 2019). In MRQA shared task the participants had to train on one set of datasets and generalize to another (Fisch et al., 2019).
Clearly, this approach enables using all the datasets already prepared by the community, and together they offer much more variety than is possible within any one dataset. However, there is also a problem: if the texts are not matched by domain, length and discourse structure, and come with different question distributions, the model could learn what kinds of questions are asked of what texts. In that sense, the QuAIL strategy provides a more general signal because the same kinds of questions are asked of all texts (but, as mentioned above, this limits both the possible question and text types).
Machine language understanding is far from being solved, but it’s fair to say we’re making progress, and the findings from all the above approaches will hopefully fuel a new generation of verbal reasoning benchmarks. Stay tuned for our tutorial at COLING 2020, which will provide both the latest updates in data collection methodology, and the dos and don’ts for the practitioners who don’t want their models to cheat.
Update: Vaiance in fine-tuning
After the QuAIL paper was published, NLP community started raising concerns about stability of fine-tuning pre-trained language models (Dodge et al., 2020). We revisited our original experiment with BERT, evaluating 8 random initializations and 8 different train/dev splits. We also released QuAIL 1.2, fixing the issue with missing questions in some texts (less than 2% of all questions were affected).
The results are as follows (the error bars indicate standard deviation across runs).
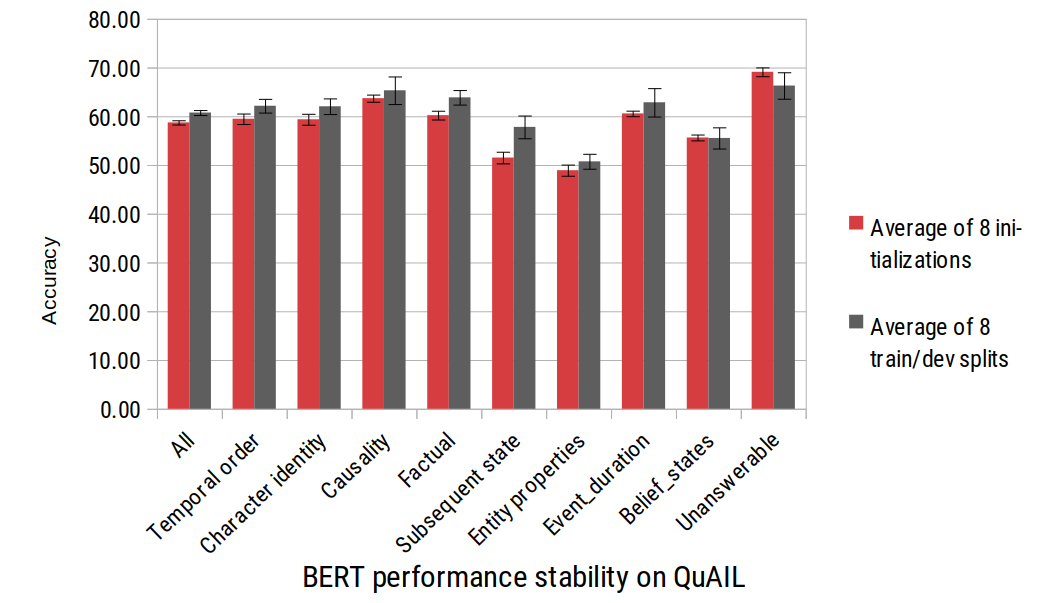
These experiments confirmed that BERT exhibits considerable variation in both conditions. Random initializations vary within 1-2%, and data splits have 2-5.5% standard deviation. The least stable categories are causality, unanswerable questions, and event duration. In particular, in our published experiment BERT was apparently very unlucky with character identity and unanswerable questions, and we got the wrong impression of its properties. We hope our experience would serve as a warning on any conclusions about architecture advantages and model properties that are based on single runs. Unfortunately, this includes the results on most of the public NLP leaderboards.
It is not clear at the moment how best to handle the potential variation in the models in the context of NLP competitions and leaderboards, especially when we also have huge variance in model size, computation budget, and volume of pre-training data. Ideally, we would all be able to run each submission multiple times, and have much larger hidden test sets, but this is not realistic. Barring that, for each submission we should at least estimate the variation due to environment factors and data splits, and not take too seriously any leaderboard gains that fall within that. Topping the leaderboard does not necessarily prove the superiority of architecture.
Our leaderboard has a hidden test set and a standard train/dev sets. We hope that these stability experiments with BERT would provide guidance as to what could be expected from other large Transformers.
The discussion of how to design better reading comprehension tests is far from over, and we hope that QuAIL would be a useful demonstration of the possibility of balanced data design and collection, the gap between machine and human performance in decisions along the uncertainty spectrum, and the difficulties our models have with paraphrased questions. We also hope that it would encourage a more thoughtful approach to benchmarking QA models by providing the domain and question type labels for the dev set2, which can be used for analysis and diagnostics of model performance.
-
The principles for paraphrasing different types of questions are outlined in this document in the project repo. ↩
-
For the train set we opted to not release these labels, so as to not tempt people to use them as features for training. ↩
References
- Zhou, B., Khashabi, D., Ning, Q., & Roth, D. (2019). “Going on a Vacation” Takes Longer than “Going for a Walk”: A Study of Temporal Commonsense Understanding. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3361–3367. https://doi.org/10.18653/v1/D19-1332 [PDF]
- Yatskar, M. (2019). A Qualitative Comparison of CoQA, SQuAD 2.0 and QuAC. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2318–2323. [PDF]
- Weston, J., Bordes, A., Chopra, S., Rush, A. M., van Merriënboer, B., Joulin, A., & Mikolov, T. (2016). Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks. ICLR 2016. [PDF]
- Wang, L., Sun, M., Zhao, W., Shen, K., & Liu, J. (2018). Yuanfudao at SemEval-2018 Task 11: Three-way Attention and Relational Knowledge for Commonsense Machine Comprehension. Proceedings of The 12th International Workshop on Semantic Evaluation, 758–762. https://doi.org/10.18653/v1/S18-1120 [PDF]
- Talmor, A., & Berant, J. (2019). MultiQA: An Empirical Investigation of Generalization and Transfer in Reading Comprehension. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4911–4921. https://doi.org/10.18653/v1/P19-1485 [PDF]
- Schmeichel, B. J., Vohs, K. D., & Baumeister, R. F. (2003). Intellectual Performance and Ego Depletion: Role of the Self in Logical Reasoning and Other Information Processing. Journal of Personality and Social Psychology, 85(1), 33.
- Rogers, A., Kovaleva, O., Downey, M., & Rumshisky, A. (2020). Getting Closer to AI Complete Question Answering: A Set of Prerequisite Real Tasks. Proceedings of the AAAI Conference on Artificial Intelligence, 8722–8731. [PDF]
- McCoy, T., Pavlick, E., & Linzen, T. (2019). Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3428–3448. https://doi.org/10.18653/v1/P19-1334 [PDF]
- Kocisky, T., Schwarz, J., Blunsom, P., Dyer, C., Hermann, K. M., Melis, G., & Grefenstette, E. (2018). The NarrativeQA Reading Comprehension Challenge. Transactions of the Association for Computational Linguistics, 6, 317–328. [PDF]
- Jia, R., & Liang, P. (2017). Adversarial Examples for Evaluating Reading Comprehension Systems. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2021–2031. https://doi.org/10.18653/v1/D17-1215 [PDF]
- Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S., & Smith, N. A. (2018). Annotation Artifacts in Natural Language Inference Data. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 107–112. https://doi.org/10.18653/v1/N18-2017 [PDF]
- Geva, M., Goldberg, Y., & Berant, J. (2019). Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1161–1166. https://doi.org/10.18653/v1/D19-1107 [PDF]
- Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., & Gardner, M. (2019). DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2368–2378. [PDF]
- Dua, D., Gottumukkala, A., Talmor, A., Gardner, M., & Singh, S. (2019). ORB: An Open Reading Benchmark for Comprehensive Evaluation of Machine Reading Comprehension. Proceedings of the 2nd Workshop on Machine Reading for Question Answering, 147–153. https://doi.org/10.18653/v1/D19-5820 [PDF]
- Dodge, J., Ilharco, G., Schwartz, R., Farhadi, A., Hajishirzi, H., & Smith, N. (2020). Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. ArXiv:2002.06305 [Cs]. [PDF]
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. [PDF]
- Bras, R. L., Swayamdipta, S., Bhagavatula, C., Zellers, R., Peters, M., Sabharwal, A., & Choi, Y. (2019). Adversarial Filters of Dataset Biases. [PDF]
- Bisk, Y., Zellers, R., Bras, R. L., Gao, J., & Choi, Y. (2020). PIQA: Reasoning about Physical Commonsense in Natural Language. AAAI. [PDF]
- Bartolo, M., Roberts, A., Welbl, J., Riedel, S., & Stenetorp, P. (2020). Beat the AI: Investigating Adversarial Human Annotations for Reading Comprehension. ArXiv:2002.00293 [Cs]. [PDF]