BERT Busters: Outlier Dimensions that Disrupt Transformers
31 Aug 2021 • 8 mins
8 mins
Tags:

Intro: Meet the BERT Busters!
Multiple studies have shown that Transformers are remarkably robust to pruning. You can often afford to lose half the model parameters, both with removing architecture blocks such as heads and layers (Prasanna, Rogers, & Rumshisky, 2020) and magnitude-based pruning (Chen et al., 2020). Overparametrization makes these models easy to compress afterwards (see surveys on compressing Transformer-based LMs (Ganesh et al., 2020; Rogers, Kovaleva, & Rumshisky, 2020).
Yet pre-trained Transformer encoders do have an Achilles’ heel. In our new paper (Kovaleva, Kulshreshtha, Rogers, & Rumshisky, 2021), we found that they are surprisingly fragile to the removal of a very small number of features in the layer outputs (<0.0001% of model weights). This effect is present in several BERT-family models and other popular pre-trained Transformer architectures, including BART, XLNet and ELECTRA, and we also found a similar phenomenon in GPT-2.
We find that across different architectures, the last operation of the Transformer layer has high-magnitude weights in the same position in different layers of the model. This results in high-magnitude values in that position in the embeddings computed by the model for 95% of the inputs. We call them outlier features.
In case of BERT and other pre-trained encoder Transformers, the affected components are the scaling factors and biases in the output LayerNorm of unusually high magnitude. Here’s what the culprits look like in BERT-base:
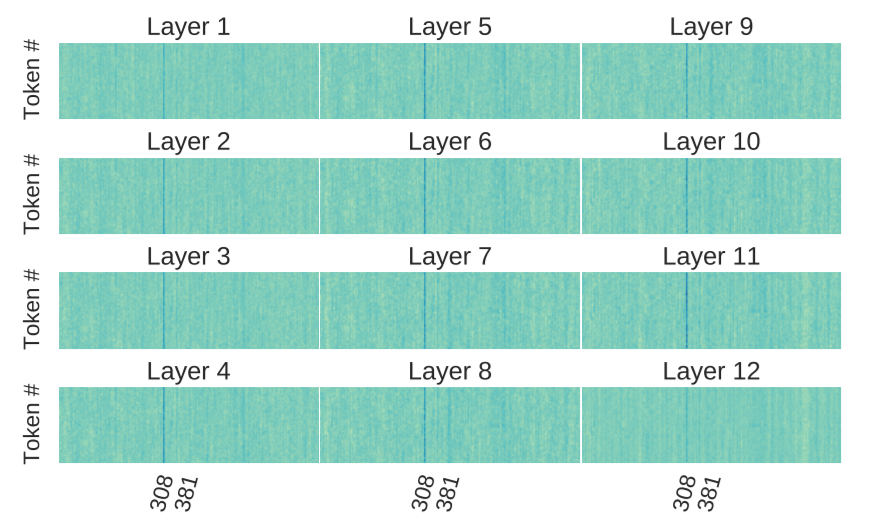
What do the outlier dimensions do?
If we selectively disable these outlier dimensions, the model is severely disrupted. To see what it does to the masked language model, let’s ask RoBERTa to fill in some blanks for us. The text in the table below comes from Wikipedia, which the model is well familiar with, and so in line 2, RoBERTa doesn’t have any issues filling in the blanks with words that match the original words (light green), or differ from them, but are valid substitutions (brown). In line 3 we see that disabling the outlier features completely disrupts the model, which now mostly produces nonsensical candidates for the masked tokens. In line 4, as a sanity check we disable the same number of random features throughout the model as the number of outliers, but the output is not affected at all.
| Original paragraph | Ghostbusters was [released] on June 8 , [1984] , to critical [acclaim] and became a cultural phenomenon . It was well [received] for its deft blend of comedy, [action] , and horror , and Murray ' s performance was [repeatedly] singled out for praise . |
| RoBERTa (full model) | Ghostbusters was [released] on June 8 , [1986] , to critical [acclaim] and became a cultural phenomenon . It was well [received] for its deft blend of comedy, [action] , and horror , and Murray ' s performance was [often] singled out for praise . |
| Roberta with outlier dimensions disabled | { lock was [never] on June 8 , [</s>] , to rely [,] and . It was well [known] for its acker of comedy , [dinner], and horror , and Murray ' s was [ever] , </s> </s> ) |
| Roberta with random dimensions disabled | Ghostbusters was [released] on June 8 , [1986] , to critical [acclaim] and became a cultural phenomenon . It was well [received] for its deft blend of comedy, [action] , and horror , and Murray ' s performance was [particularly] singled out for praise. |
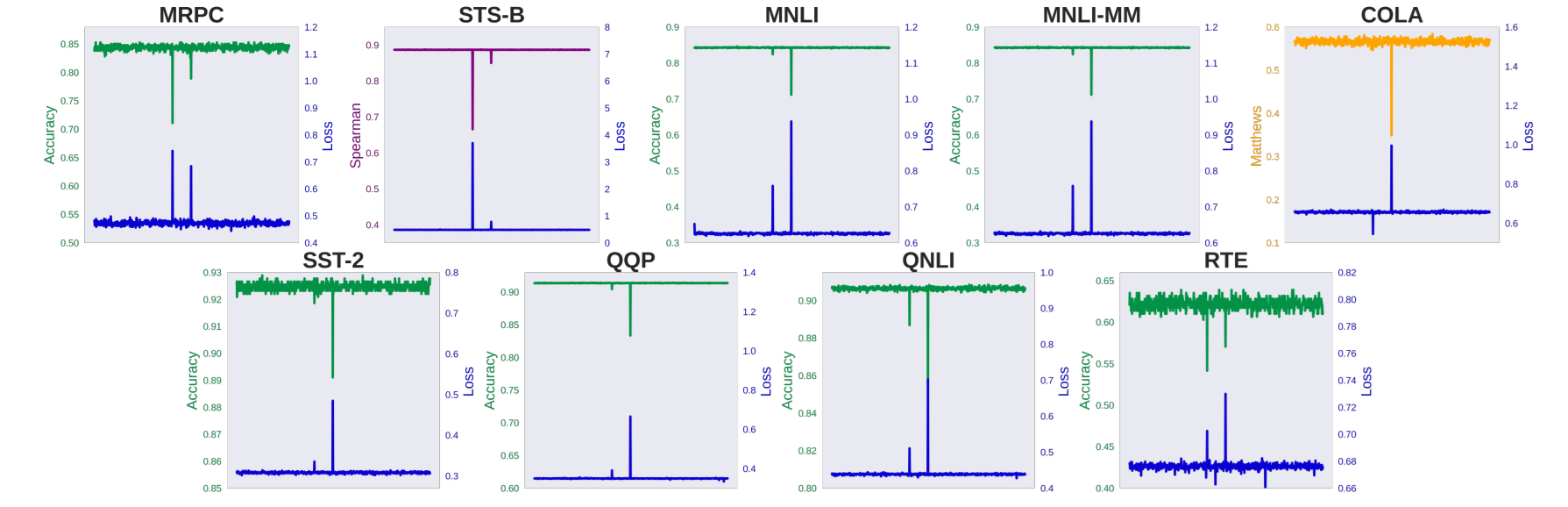
The downstream tasks take a hit too. Here is what happens with BERT-base on GLUE when one outlier dimension is disabled at a time:
Is this a bug or a feature?
To begin this, the outlier dimensions do not seem to be an artifact of a particular model instance. We found such dimensions in all six models of BERT family that we considered: BERT-small, BERT-medium, BERT-base, BERT-large, mBERT and RoBERTa. They are also found in ELECTRA, XLNet, and BART. A similar phenomenon is present in the output dense layer of GPT-2, (since there the output component is not LayerNorm). It seems that this is a normal effect of pre-training in these models.
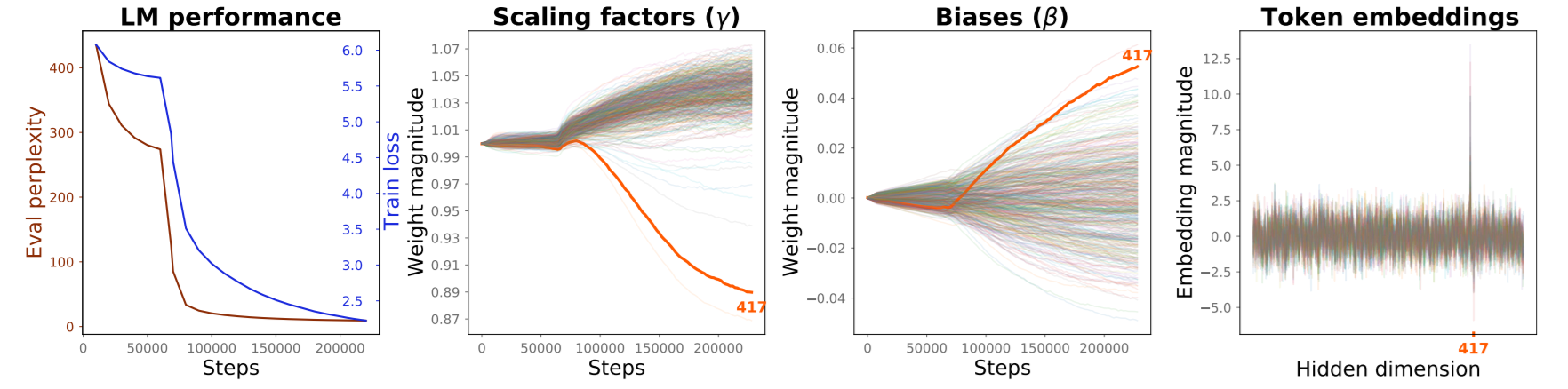
To find out when the outliers appear, we pre-train our own BERT-medium model on BookCorpus (Zhu et al., 2015). We started from a randomly initialized configuration with 8 layers and the hidden dimensionality of 512 units. We saved checkpoints of the model every 2000 steps, and we tracked the output LayerNorm weights across all of the model’s layers as the training progressed. Figure 3 shows that both scaling factors and biases begin to diverge from their initialization values quite early (after approximately 50k steps) in the training process. At roughly the same point, both training loss and evaluation perplexity begin to improve, which is in line with the drastic effect on model performance that we saw in the above pruning experiments.
How is this related to positional embeddings?
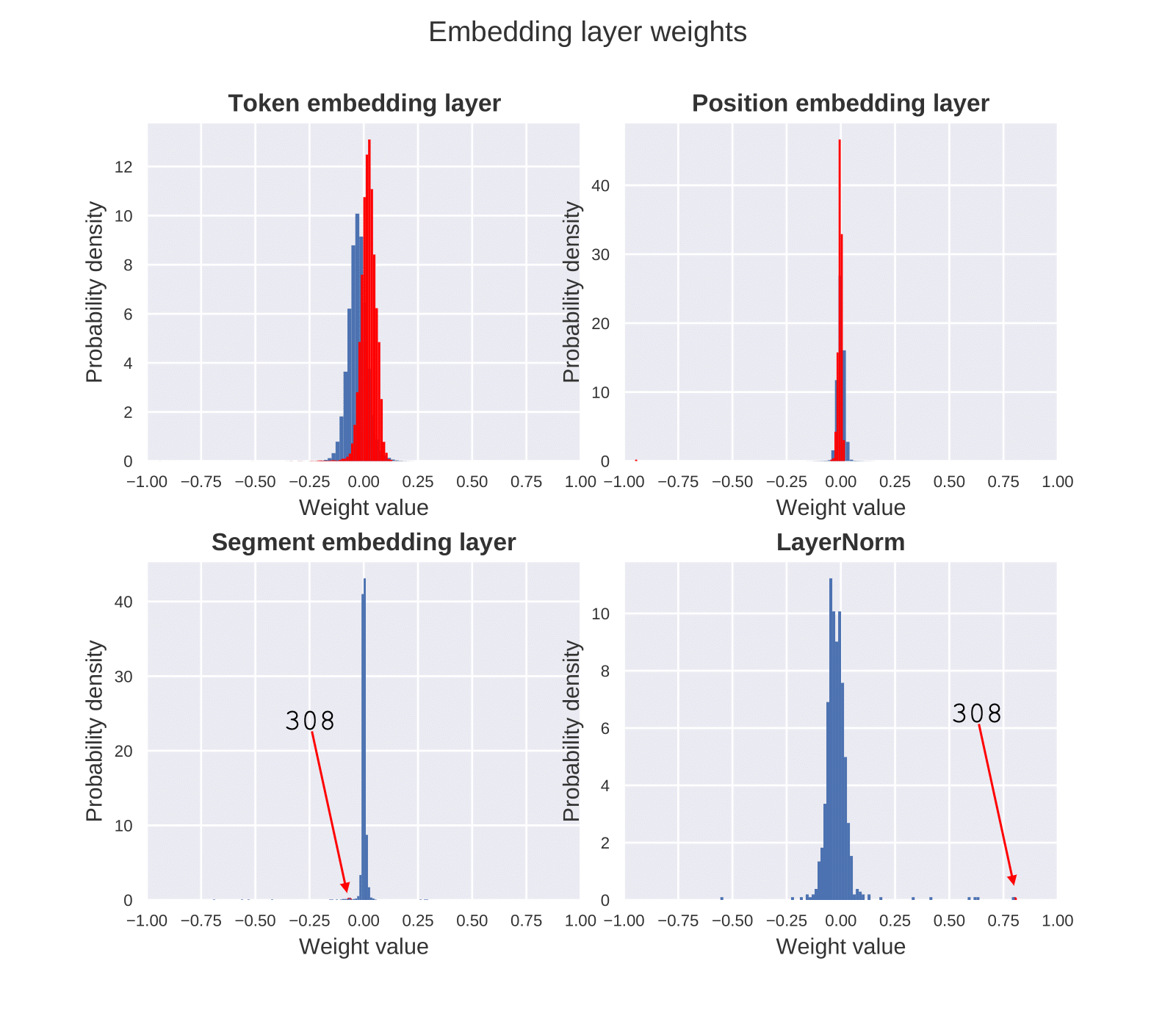
In a concurrent work, (Luo, Kulmizev, & Mao, 2021) hypothesized that the outlier phenomenon is attributable to the positional embedding layer. We argue (Kovaleva, 2021) it is much more likely that this effect comes from the LayerNorm component of the embedding layer.
The histogram in Fig 4. shows that it’s only the LayerNorm of the embedding layer that has unusual outlier values in the specified dimension. The distribution of weights in the other three components of the embedding layer – lexical, positional, and segment embeddings – is centered around zero and forms Gaussian-shaped curves with a small standard deviation. Compared to the other components, LayerNorm weights have a much higher variance of values, with the highest weight matching the outlier position 308. We hypothesize that the learned weights of LayerNorm in the embedding layer are responsible for producing high-magnitude outlier features that are propagated through the rest of the network resulting in the consistent outlier effects across the Transformer layers.
Where do we go from here?
So… if BERT can be completely disrupted by disabling so few weights, how come this phenomenon hasn’t been seen in all the pruning studies so far? The catch is that it is not just about the weight magnitude. The outlier dimensions have to be pruned in the exact same position across the model, and neither magnitude pruning nor pruning attention heads based on their importance scores have that constraint. So, simply by not pruning the same positions across the model, the pruning studies have been avoiding the outlier iceberg. Just to avoid degenerate runs by chance, we would recommend that work on pruning/compressing Transformers explicitly puts in the constraint that the pruned weights should not be in the same position across the model.
Now that we know about the outliers, they are an obvious security risk: if a malicious actor gains access to the weights of a model, they could easily identify such weights and modify them (e.g. in a federated learning context). It would look like the model is still running as expected, except that its output would turn into garbage.
And, since the outlier dimensions seem to be a regular feature of Transformer-based models, this brings up a host of interesting questions for future work:
- Is it possible to pre-train a Transformer that wouldn’t have such outliers?
- If they are necessary, shall we save ourselves trouble and initialize the model that way?
- Can their emergence in pre-training be used as an auxiliary signal for when the model training is completed?
- Is 2-3 outlier features necessary sufficient, or will the model quality be improved by creating more of them?
References
- Zhu, Y., Kiros, R., Zemel, R., Salakhutdinov, R., Urtasun, R., Torralba, A., & Fidler, S. (2015). Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. Proceedings of the IEEE International Conference on Computer Vision, 19–27. [PDF]
- Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). A Primer in BERTology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics, 8, 842–866. https://doi.org/10.1162/tacl_a_00349 [PDF]
- Prasanna, S., Rogers, A., & Rumshisky, A. (2020). When BERT Plays the Lottery, All Tickets Are Winning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 3208–3229. Online: Association for Computational Linguistics. [PDF]
- Luo, Z., Kulmizev, A., & Mao, X. (2021). Positional Artefacts Propagate Through Masked Language Model Embeddings. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 5312–5327. https://doi.org/10.18653/v1/2021.acl-long.413 [PDF]
- Kovaleva, O., Kulshreshtha, S., Rogers, A., & Rumshisky, A. (2021). BERT Busters: Outlier Dimensions that Disrupt Transformers. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 3392–3405. https://doi.org/10.18653/v1/2021.findings-acl.300 [PDF]
- Kovaleva, O. (2021). Transformer Models in Natural Language Understanding: Strengths, Weaknesses, and Limitations (PhD thesis). University of Massachusetts Lowell.
- Ganesh, P., Chen, Y., Lou, X., Khan, M. A., Yang, Y., Chen, D., … Nakov, P. (2020). Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. ArXiv:2002.11985 [Cs, Stat]. [PDF]
- Chen, T., Frankle, J., Chang, S., Liu, S., Zhang, Y., Wang, Z., & Carbin, M. (2020). The Lottery Ticket Hypothesis for Pre-Trained BERT Networks. ArXiv:2007.12223 [Cs, Stat]. [PDF]